(3)
(3)
2013-2-1記
数独の類似問題について考える
▼私は、今まで新聞や雑誌に紹介される数独パズルの問題を解いては、それを個人的に保存してきた。その問題の総数が400件近くになってきている。そこで、かねてから気になっていたことに挑戦してみようと考えた。
数独の問題の組み合わせは ほぼ無限(*1)にあるが、実際に自分で問題を作るとなるとこれが結構難しい。難しいという意味にも色々あって、新しい問題を作ることはもちろん難しいけれど、その他に既存の問題とは異なる新しいものであることを確認する作業の方が大変だからである。そのため、誰も確認などしないでそのまま公表しているのが現実なのではないかと思う。
【注】(*1)約54億パターン以上あると言われている。
そうなると、既存の問題と偶然に一致した問題が作られても、誰もそれに気が付かないまま新しい問題だと思い込んでいる可能性も十分にあり得るのではないか。沢山の問題を集めて「問題集を持っている」などと威張っていても、かなり類似した(あるいは全く同じ)問題が含まれているかもしれない。そういう素朴な疑問を(愚かにも)私めは持ってしまったのである。ほぼ無限の組み合わせパターンが存在するのだから、そんなことは考えるだけ無駄だと言う人の方が多いのかもしれないが。
そこで、愚かな私めは この約400個の問題に対して、同じものが含まれていないか確認するプログラムを作ってみようと思い立った。以前から Perl言語を使えば簡単にできるのではないかと考えていたからである。
▼Perlでプログラムを記述する際に、私はハッシュ(hash)(*2)というデータ記憶方式を利用することにした。これは人間の脳の記憶方法を真似たもので、実に使い勝手がよい。
人間の脳は、既存のものとの類似度を調べて“初出”(初めて出現したものかどうか)を簡単に判別できる機能を持っている。
【注】(*2)Perlの初期の版では、連想変数(associated variable)
と呼ばれていた。
たとえば、受験勉強の時の経験だが、意味の分からない英単語に出会うと辞書を引いて調べる。そして辞書の中でその単語を見つけた瞬間、以前調べたことのある単語だと気が付いて悔しい思いをすることが多い。それが何度も繰り返されると、かなり落ち込むことになる。そして自分の記憶力に自信がなくなってきたりする。
しかしよくよく考えてみると、以前一度調べたことがあるという“事実”の方はしっかりと記憶されていることに気が付く。だからこそ、悔しい思いをするのである。忘れているのは、実は“意味”の方だけなのだ。人間の脳は“初出”だけはしっかりと記憶していて、素早く反応してその事実を教えてくれる。
年寄りが同じ話を繰り返すと、それを聞いた若者の脳は素早く「初出ではない」ことを感知して「その話は聞いたよ!」と返すことになる。中には「その話、3回目だよ!」などと回数まで記憶している人もいる。
人間は齢を取ると記憶力が衰えるから、同じ話を繰り返すようになるのだと理解しているとすれば、それは少し違うのではないかと思う。年寄りでも初出はしっかりと覚えている。その証拠に、何度も同じ話をしていると段々と話し方がうまくなってきて、場合によっては一部が誇張され更に面白い話に脚色されてしまったりする。だから、初出でない(つまり、その話を以前したことがある)という事実は十分に記憶されているのである。年寄りが忘れてしまうのは「誰に対してその話をしたか!」ということの方なのである。
我々は(年寄りも含めて)この機能をもっと自信を持って活用した方がよいと思う。
▼そこで、年寄りである私めも この初出識別の機能をプログラムの上ではあるが、使用してみることにした。
早速、Perl言語でプログラムを作って手持ちの約400個のデータで試してみた。
その結果は、自分でも驚くほどのものであった。
・同じ問題が3個見つかったケース(2回)
・同じ問題が2個見つかったケース(3回)
つまり、12個の問題が実際は5個になってしまったのである。
しかし冷静に分析してみると、私の問題集に重複登録されてしまったのは、どうやら大半は私の方の整理ミスが原因であるように思われる。最初の頃は個々の問題に適当に命名していたので、データベース化する時点で別のものと判断されたのかもしれない。その反省を踏まえ、現在は統一した命名法で出典を辿れるようにしてある。
もう一つの原因は、「例題-1」という名称の問題だったから、以前に発表した問題を「例」として取り上げたのであろう。それを、私が問題の一つとして登録してしまったのが原因ではないかと思う。何しろ最初の頃は、沢山の問題を手に入れようと夢中になっていたから無理もなかろうと思う。
結果として「偶然の一致」と確認できたものは一つも存在しなかった。
▼この“初出”を確認するプログラムが実用的かどうか確認するには、もっと沢山の数独問題が必要となる。そこで私は、あるサイト上から問題をまとめて入手することを試みた。
このサイト上では、毎日定期的に新しい問題が出題されているらしい。その各画面上から、9x9のます目の中に埋め込まれたデータ部分だけを抜き出してくるのである。人手で一つ一つデータを書き写していたのでは時間が掛かり過ぎて現実的ではない。そこで、あらかじめデータの構造を調べておいて、それに対応する抜き出しプログラムを作ることにした。これを利用してすべて自動的に抜き出してしまおうという魂胆である(プログラム作りのネタはいたる所にあるものだ)。
その結果、プログラム作りの時間も含めて多少時間は掛かったが、34,125個の問題を一挙に手に入れることができた。
“初出”を確認するプログラムにこのデータを入力してみたところ、類似した問題は一つも含まれていないことが確認できた。数独作りの立場からは「期待通りの結果」ではあったが、プログラム作りの立場からは「少し残念」な気もした。一つくらい発見されるのではないかと密かに期待していたのである。
そこで、類似度を確認する方法をより高度なものにしたバージョン(V2.0)を作成した。そのプログラム(下記参照)を利用すると「類似している」とみなされる問題が1件検出されたのである。ただ、これは偶然似てしまったものであろう。読者の皆さんも自分で目で確認してみるとよい。
ともあれ、3万4千個余りの膨大な問題データが(文字通り)あっという間に処理されて、結果が表示されたのは痛快であった。これなら十分に実用になりそうである。読者も試してみてください。
ところで、正式に公開されている数独問題とはいえ、このようにデータ構造を調べて(プログラムで)データの一部だけを抜き出すという行為は、はたして倫理的に許される行為なのだろうか。いささか疑問が残る。この作業をしながら自分が(ブラックハットの)ハッカーになったような気がしたことを白状しなければならない。検査のために使うだけにして、終了後は破棄する方が無難であろう。こんな膨大な数の数独問題を持っていても、到底すべてを解くことなどできないのだから。■
▼プログラム(数独問題の類似度をチェックするプログラム)を以下に示す。
このプログラムに与えるデータの構造は以下の通り。
<data-name> := 問題の名称 (出典が分かるようにする)
<data-string> := 000304000.........9010 (例)
(81(=9x9)桁の数列を書く。空白のます目の値は "0" とする)
とすると、
1つの問題のデータは、次のようにタブコードで区切られた1行にまとめられて表現されている。
<data-name> <タブコード> <data-string> <改行コード>
この行からなるデータを、作成された年度毎に1つのファイル(例えば "SD2013.txt")としてまとめておくと便利である(複数ファイルを指定可)。
以下のプログラム例では、"SD1995.txt" から "SD2013.txt" まで19個のファイルに問題が記憶されている。この部分(青字の部分)を書き変えれば、任意のファイル名を指定できるよう改造するのは容易であろう。(ただし、ここで紹介したプログラムは、HTMLファイルとして表示するためにテキスト部分に手を入れています。したがって、厳密にはソースプログラムそのままではなく、どこかにミスが入り込んでいるかもしれません。)
このプログラムを実行するには、Perl処理系が必要です。Perlは、誰でも無料で入手できます。入手先は「Active Perl」で検索すればすぐみつかります。
<数独問題の類似度をチェックするプログラム>
# 数独問題の類似度をチェックするプログラム(V2.0)
# (c) 2013-1-28 coded by knuhs
my %SDpool;
my ($SDname, $SDdata);
my $SDcounter;
my @data;
my @datalist = ( 1995 .. 2013 );
my $total = 0;
print "** 類似の数独問題が存在するかどうか検査します。\n";
# 問題データの読込み
foreach my $d ( @datalist )
{
$dname = "SD$d.txt";
print "\* $dname start..... ";
open( SuUDOKU, $dname ) || die "開けません。$!";
$SDcounter = 0;
while( <SuUDOKU> )
{
chomp;
next if $_ eq '';
$SDcounter++;
( $SDname, $SDdata ) = ( m/^(.*?)\t(.*)$/ );
$_ =~ m/(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\
d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{
3})(\d{3})(\d{3})(\d{3})/;
@data = ($1.$4.$7, $2.$5.$8, $3.$6.$9, $10.$13.$16, $11.$14.$17, $12.$15.$18, $1
9.$22.$25, $20.$23.$26, $21.$24.$27 );
@data = map { join '', sort split '', $_ } @data;
$_ = join '', sort map { s/0(?!$)//g; $_ } @data;
my $i = ++$SDpool{ $_ }[0];
$SDpool{ $_ }[$i*2-1] = $SDname;
$SDpool{ $_ }[$i*2] = $SDdata;
}
print "($SDcounter個)\n";
$total += $SDcounter;
close( SuUDOKU );
}
# 結果の出力
print "** 検査結果 ** (計 $total個の問題を検査しました)\n";
my $none=1;
foreach my $pname( keys %SDpool )
{
my $count = $SDpool{ $pname }[0];
next if $count==1;
print "\n* 類似の問題が $count個見つかりました。\n";
for( my $index=1; $index<=$count; $index++ )
{
print " ($index)$SDpool{ $pname }[$index*2-1]";
print "\nDATA=\"$SDpool{ $pname }[$index*2]\"\n";
}
$none=0;
}
print "\n 類似の問題はありません。" if $none;
print "\n*** チェック終了 ***";
|
<実行結果の例>
** 類似の数独問題が存在するかどうか検査します。
* SD1995.txt start..... (1252個)
* SD1996.txt start..... (1830個)
* SD1997.txt start..... (1825個)
* SD1998.txt start..... (1825個)
* SD1999.txt start..... (1825個)
* SD2000.txt start..... (1830個)
* SD2001.txt start..... (1825個)
* SD2002.txt start..... (1825個)
* SD2003.txt start..... (1825個)
* SD2004.txt start..... (1830個)
* SD2005.txt start..... (1825個)
* SD2006.txt start..... (1825個)
* SD2007.txt start..... (1825個)
* SD2008.txt start..... (1830個)
* SD2009.txt start..... (1825個)
* SD2010.txt start..... (1825個)
* SD2011.txt start..... (1825個)
* SD2012.txt start..... (1830個)
* SD2013.txt start..... (1825個)
** 検査結果 ** (計 34127個の問題を検査しました)
* 類似の問題が 2個見つかりました。
(1)Sample-1
DATA="000573100400080009000006078049012063806307040001004205653128497700639502192005800"
(2)Sample-2(Sample-1の真似)
DATA="653128497700639502192005800000573100400080009000006078049012063806307040001004205"
* 類似の問題が 2個見つかりました。
(1)XXXXX 2002-11-24(LVL=2)
DATA="000200001008000050000300000400000600210000000000050080300000002000060400009080000"
(2)XXXXX 2009-6-14(LVL=2)
DATA="000060300040080000002000009000003000500000800001200000060000042800050000000000001"
*** チェック終了 ***
|
▼類似していると判定された問題についての説明
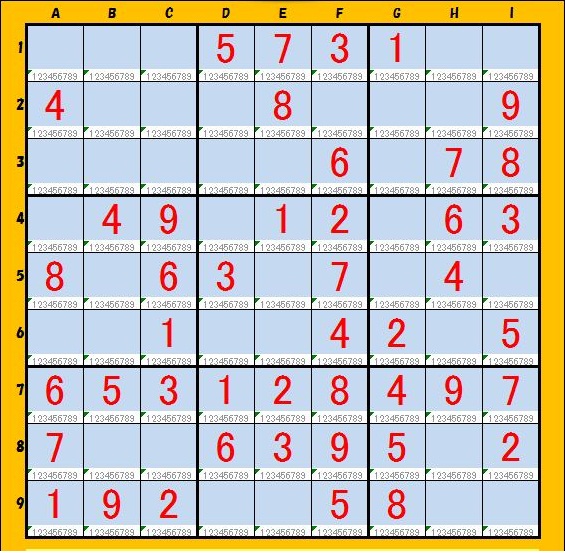
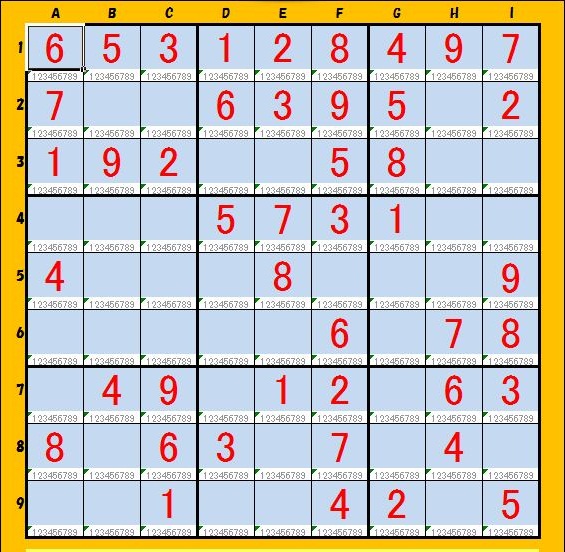
(1)Sample-1 と Sample-2
9個のブロックの位置を入れ替えて、わざと類似問題を作ってみました。簡単に見破られたようです。
Sample-1 Sample-2
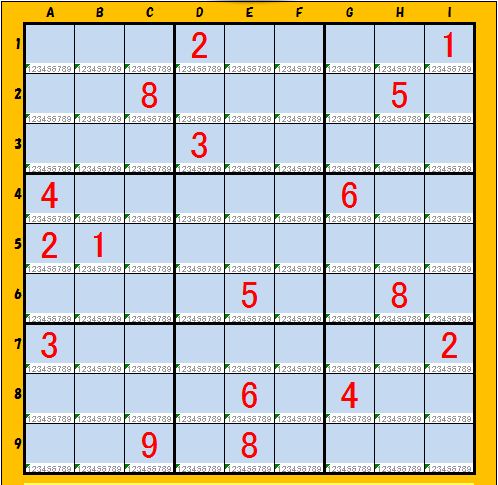
(2)2002-11-24作 と 2009-6-14作:初期値設定が偶然合致したケース
大量の問題の中から偶然発見されたものです。9個のブロックに置かれた初期値の組み合わせがすべて一致していることが分かります。類似度を検出する際に私がどういう手法を使ったか推察できるでしょう。それがうまく作動したので作者としては大変満足しておりますが、この問題は偶然の一致ですから更なるアルゴリズムの改良が必要であることを意味しています。読者の皆さんの感想を知りたいものです。
2002-11-24の作品 2009-6-14の作品
|