< 数独問題の類似度をチェックするプログラム >
# 数独問題の類似度をチェックするプログラム(V3.0)
# (c) 2013-2-2 coded by knuhs
my %SDpool;
# 初期設定
my @datalist = ( 'SD1994.txt', 'SD1995.txt' ); # 問題集ファイル(適当に書き替える)
my $Debug = 1; # =1 なら内部情報を出力する。=0 なら出力しない
print "** 類似の数独問題が存在するかどうか検査します。\n";
# 問題データの読込み
my $total = 0; # 問題の総数を記録する
foreach my $fname ( @datalist )
{
print "\* $fname start..... ";
open( SuUDOKU, $fname ) || die "開けません。$!";
my $SDcounter = 0; # 各ファイルに含まれる問題の数を記録する
while( <SuUDOKU> )
{
chomp; # 改行コードを削除
next unless $_ ; # 空白行は読み飛ばす
$SDcounter++;
( my $SDname, my $SDdata ) = ( m/^(.*?)\t(.*)$/ ); # 問題名と初期値データを取り出す
# 初期値データから、各ブロックに属する初期値列を求め“キー”として用いる
$SDdata =~ m/(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})(\d{3})/;
my @data = ( $1.$4.$7, $2.$5.$8, $3.$6.$9, $10.$13.$16, $11.$14.$17, $12.$15.$18, $19.$22.$25, $20.$23.$26, $21.$24.$27 );
@data = map { join '', sort split '', $_ } @data;
$_ = join '', sort map { s/0(?!$)//g; $_ } @data; # キーをソートし標準形式にする
$i = ++$SDpool{$_}[0]; # キーを登録し出現回数を記録する
$SDpool{$_}[$i][0] = $SDname; # キーの基に問題名と
$SDpool{$_}[$i][1] = $SDdata; # 初期値データを保存する
}
print "($SDcounter個)\n"; # 各ファイル毎の問題の数を表示
$total += $SDcounter; # 問題の総数を記録する
close( SuUDOKU );
}
# 結果の判定
print "** 検査結果 ** (計 $total個の問題を検査しました)\n";
my $none = 1; # 類似問題がない(初期設定)
foreach my $sdkey( keys %SDpool ) # キーを取り出し
{
my $count = $SDpool{$sdkey}[0]; # 出現回数から類似問題がないか調べる
next if $count==1; # 重複なし(=1)ならば次へ
print "\n* 類似の問題が $count個見つかりました。\n";
for( my $index=1; $index<=$count; $index++ )
{
my $initVal = $SDpool{$sdkey}[$index][1]; # 初期設定値を取り出す
print " ($index)$SDpool{$sdkey}[$index][0]\n"; # 問題名を出力
print " [0]キー値=\"$sdkey\"\n [1]初期値=\"$initVal\"\n" if $Debug;
# キー値と初期値を出力
# 初期値データから各行の値を求める
$initVal =~ m/(\d{9})(\d{9})(\d{9})(\d{9})(\d{9})(\d{9})(\d{9})(\d{9})(\d{9})/;
my @data = ( $1, $2, $3, $4, $5, $6, $7, $8, $9 ); # 行毎の初期値から行情報を作る
@data = map { join '', sort split '', $_ } @data; # 行情報を標準形式にする
my $Col = join '', sort map { s/0(?!$)//g; $_ } @data;
$SDpool{$sdkey}[$index][2] = $Col; # 行情報の保存
# 初期値データから各列の値を求める
@data = split '', $initVal;
my @RC;
for ( my $n = 0; $n <= 8; $n++ ) # 行と列を入れ替える
{ $RC[$n] = join '', @data[$n, $n+9, $n+18, $n+27, $n+36, $n+45, $n+54, $n+63, $n+72]; }
@data = map { join '', sort split '', $_ } @RC; # 列情報を標準形式にする
my $Row = join '', sort map { s/0(?!$)//g; $_ } @data;
$SDpool{$sdkey}[$index][3] = $Row; # 列情報の保存
print " [2]行情報=\"$Col\"\n [3]列情報=\"$Row\"\n\n" if $Debug;
# 行情報と列情報を出力
}
$none = 0; # 類似問題あり
# 最終判定
for( my $i = 1; $i <= $count; $i++ )
{ for( my $j = 1; $j <= $count; $j++ )
{ next if $i<= $j;
if ( $SDpool{$sdkey}[$i][1] eq $SDpool{$sdkey}[$j][1] )
{ print " ・($j)と($i)は、まったく同じ問題です。\n"; }
elsif ( $SDpool{$sdkey}[$i][2] eq $SDpool{$sdkey}[$j][2]
|| $SDpool{$sdkey}[$i][3] eq $SDpool{$sdkey}[$j][3] )
{ print " ・($j)と($i)は、ブロックまたは行を入れ替えただけの同じ問題です。\n"; }
elsif ( $SDpool{$sdkey}[$i][3] eq $SDpool{$sdkey}[$j][2]
|| $SDpool{$sdkey}[$i][2] eq $SDpool{$sdkey}[$j][3] )
{ print " ・($j)と($i)は、行と列を入れ替えただけの同じ問題です。\n"; }
else{ print " ・($j)と($i)は、似ていますが別物です。\n"; }
}
}
}
print "\n 類似の問題はありません。" if $none;
print "\n*** チェック終了 ***";
|
<実行結果の例>
** 類似の数独問題が存在するかどうか検査します。
* SD1994.txt start..... (4個)
* SD1995.txt start..... (1252個)
** 検査結果 ** (計 1256個の問題を検査しました)
* 類似の問題が 2個見つかりました。
(1)xxx 1995-4-26
[0]キー値="123471235679123568914689178923456245789356784"
[1]初期値="000573100400080009000006078049012063806307040001004205653128497700639502192005800"
[2]行情報="123456789123469124512589135723567934678489678"
[3]列情報="123691237812458135614678234567892357894594679"
(2)xxx 1995-4-26
[0]キー値="123471235679123568914689178923456245789356784"
[1]初期値="653128497700639502192005800000573100400080009000006078049012063806307040001004205"
[2]行情報="123456789123469124512589135723567934678489678"
[3]列情報="123691237812458135614678234567892357894594679"
・(1)と(2)は、ブロックまたは行を入れ替えただけの同じ問題です。
* 類似の問題が 4個見つかりました。
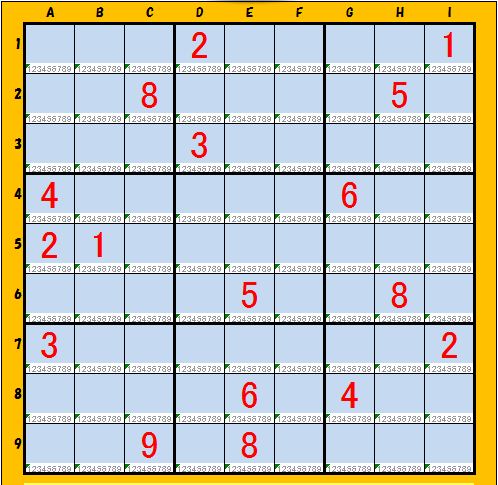
(1)XXXXX
[0]キー値="12415232439568688"
[1]初期値="000200001008000050000300000400000600210000000000050080300000002000060400009080000"
[2]行情報="12122334646585889"
[3]列情報="011223234465685889"
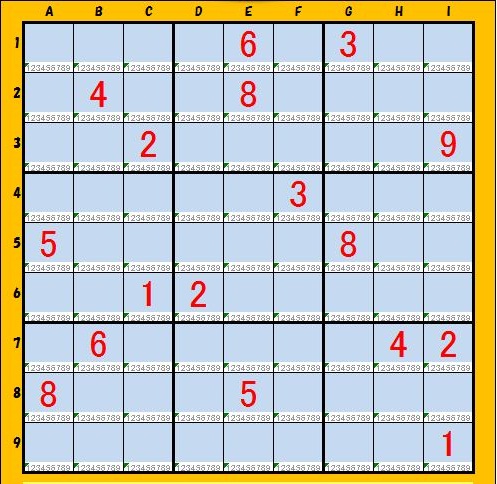
(2)YYYYY
[0]キー値="12415232439568688"
[1]初期値="000060300040080000002000009000003000500000800001200000060000042800050000000000001"
[2]行情報="11224629336485858"
[3]列情報="12129233844656858"
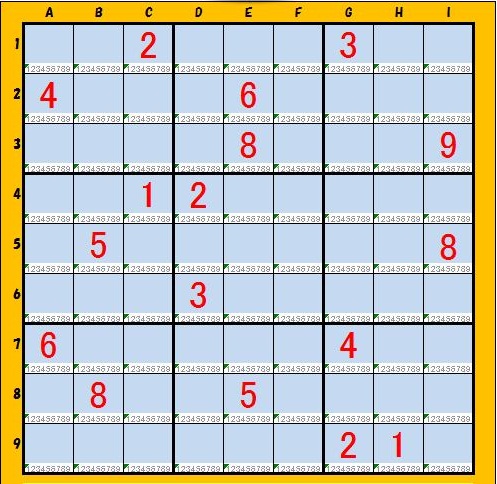
(3)ZZZZZ
[0]キー値="12415232439568688"
[1]初期値="002000300400060000000080009001200000050000008000300000600000400080050000000000210"
[2]行情報="12122334646585889"
[3]列情報="011223234465685889"
(4)AAAAA
[0]キー値="12415232439568688"
[1]初期値="040000600000500080200010000000023000068000050000000000300000402000000001009800000"
[2]行情報="011223234465685889"
[3]列情報="12122334646585889"
・(1)と(2)は、似ていますが別物です。
・(1)と(3)は、ブロックまたは行を入れ替えただけの同じ問題です。
・(2)と(3)は、似ていますが別物です。
・(1)と(4)は、行と列を入れ替えただけの同じ問題です。
・(2)と(4)は、似ていますが別物です。
・(3)と(4)は、行と列を入れ替えただけの同じ問題です。
|
(1)XXXXX (2)YYYYY
(3)ZZZZZ (4)AAAAA
このプログラムで使ったアルゴリズムの説明
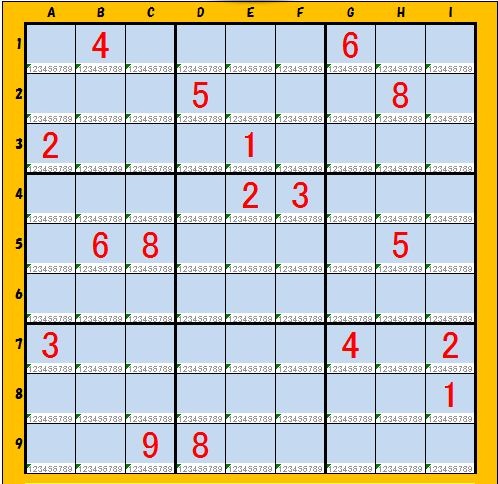
▼数独問題のパターンを比較するには、各ブロックごとの初期値から特徴を引き出す必要がある。たとえば下図の場合、
各ブロック毎の初期値をリスト形式で表すと次のようになる。
( '000008000', '200000300', '001050000',
'400210000', '000000050', '600000080',
'300000009', '000060080', '0002400000' )
ここで、初期値が設定された場所に関する情報は無視して各要素ごとにデータをソートする。ソートは数値としてのソートではなく文字コードでのソートを使っている。つまり辞書順であると思えばよい。
たとえば、
'400210000' は( split '' )でバラバラにして以下のようなリストにする。
( '4', '0', '0', '2', '1', '0', '0', '0', '0' )
これをソート( sort )すると
( '0', '0', '0', '0', '0', '0', '1', '2', '4' )
となる。これを( join '' )で再び連結して
'000000124'
の形にして、要素に戻す。この処理を全要素に対して実行すると、
( '000000008', '000000023', '000000015',
'000000124', '000000005', '000000068',
'000000039', '000000068', '000000024' )
が得られる。
次に、'0' はすべて削除する。
( '8', '23', '15', '124', '5', '68', '39', '68', '24' )
ただし '0' を削除する際に、ブロックがもともと空の場合はすべて '0' で値が残らないから、一つだけ '0' を残しておく必要がある。それには、
s/0(?!$)//g;
とする。つまり、直後に $(行末)が続かない '0' のみを削除するよう指示する。
次に全体をソート( sort )して、
( '124', '15', '23', '24', '39', '5', '68', '68', '8' )
を得る。これを連結( join '' )して
( '12415232439568688' )
を得る。
このようにして、この数独問題のパターンは、'12415232439568688' という文字列で特徴付けられることになる。これをキー文字列として用いることにする。
以上の手順を実行しているのが、以下の2行である。
@data = map { join '', sort split '', $_ } @data;
$_ = join '', sort map { s/0(?!$)//g; $_ } @data;
この $_ に得られたキー文字列に相当するパターンは、ブロックを上下左右に入れ替えても変わらないから、
・ブロック入れ替えによる類似の問題はすぐに検出できることになる。
同様に、同じことを
・行毎にやれば、行だけを入れ替えた類似の問題も検出できる。
・列毎にやれば、列だけを入れ替えた類似の問題も検出できることになる。
|


[ ] ]
|